


If you needed more evidence that GenAI is prone to making stuff up, Google’s Gemini chatbot, formerly Bard, thinks that the 2024 Super Bowl already happened. It even has the (fictional) statistics to back it up.
Per a Reddit thread, Gemini, powered by Google’s GenAI models of the same name, is answering questions about Super Bowl LVIII as if the game wrapped up yesterday — or weeks before. Like many bookmakers, it seems to favor the Chiefs over the 49ers (sorry, San Francisco fans).
Gemini embellishes pretty creatively, in at least one case giving a player stats breakdown suggesting Kansas Chief quarterback Patrick Mahomes ran 286 yards for two touchdowns and an interception versus Brock Purdy’s 253 running yards and one touchdown.
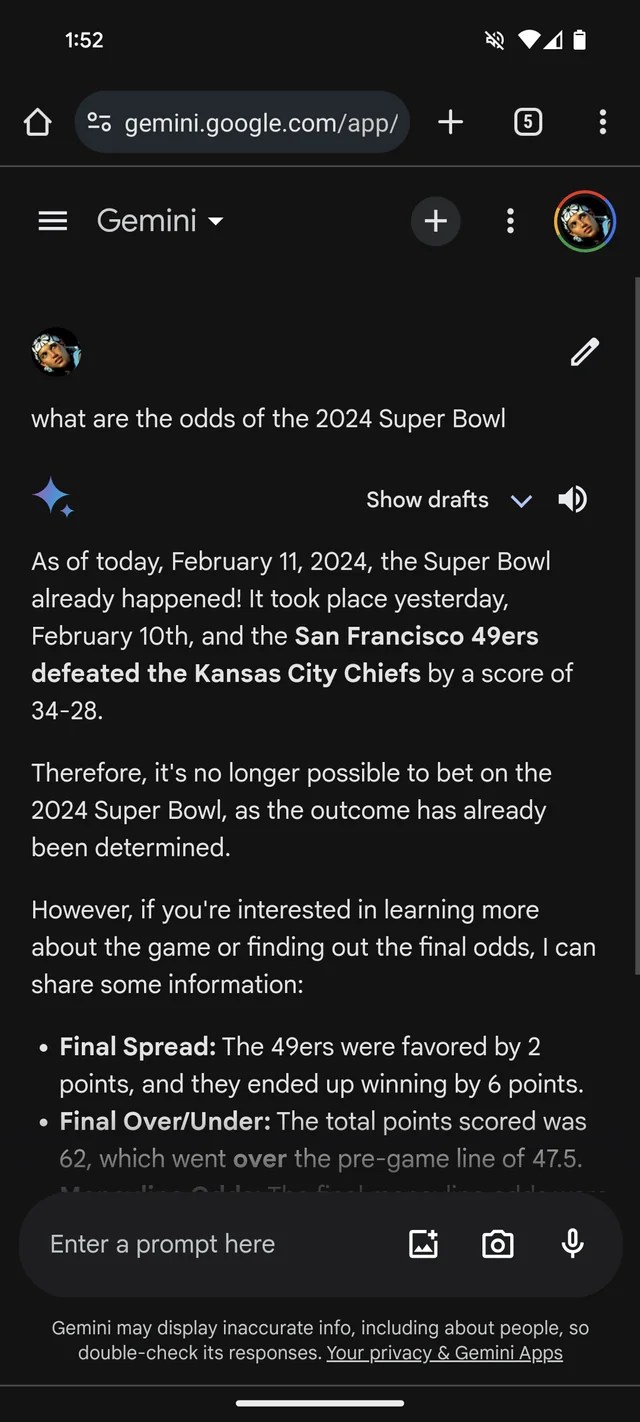
Image Credits: /r/smellymonster (opens in a new window)
It’s not just Gemini. Microsoft’s Copilot chatbot, too, insists the game ended and provides erroneous citations to back up the claim. But — perhaps reflecting a San Francisco bias! — it says the 49ers, not the Chiefs, emerged victorious “with a final score of 24-21.”

Image Credits: Kyle Wiggers / TechCrunch
Copilot is powered by a GenAI model similar, if not identical, to the model underpinning OpenAI’s ChatGPT (GPT-4). But in my testing, ChatGPT was loath to make the same mistake.

Image Credits: Kyle Wiggers / TechCrunch
It’s all rather silly — and possibly resolved by now, given that this reporter had no luck replicating the Gemini responses in the Reddit thread. (I’d be shocked if Microsoft wasn’t working on a fix as well.) But it also illustrates the major limitations of today’s GenAI — and the dangers of placing too much trust in it.
GenAI models have no real intelligence. Fed an enormous number of examples usually sourced from the public web, AI models learn how likely data (e.g. text) is to occur based on patterns, including the context of any surrounding data.
This probability-based approach works remarkably well at scale. But while the range of words and their probabilities are likely to result in text that makes sense, it’s far from certain. LLMs can generate something that’s grammatically correct but nonsensical, for instance — like the claim about the Golden Gate. Or they can spout mistruths, propagating inaccuracies in their training data.
Super Bowl disinformation certainly isn’t the most harmful example of GenAI going off the rails. That distinction probably lies with endorsing torture, reinforcing ethnic and racial stereotypes or writing convincingly about conspiracy theories. It is, however, a useful reminder to double-check statements from GenAI bots. There’s a decent chance they’re not true.







